CIFAR10 TRAINING A CLASSIFIER
Overview of pytorch
PyTorch is gaining popularity in the Deep Learning community and is widely being used by deep learning practitioners, PyTorch is a Python-based library that provides Tensor computations. Furthermore, tensors are multidimensional arrays just like NumPy’s ndarrays which can run on GPU as well.
PyTorch provides functionalities such as:- TorchScript for creating serializable and optimizable models
- Distributed training to parallelize computations
- Dynamic Computation graphs which enable to make the computation graphs on the go, and many more
PyTorch provides a framework for us to build computational graphs as we go, and even change them during runtime. Particularly, this is valuable for situations where we don’t know how much memory for creating a neural network. You can work on all sorts of deep learning challenges using PyTorch.
The following are some of the challenges:- Images (Detection, Classification, etc.)
- Text (classification, generation, etc.)
- Reinforcement Learning
The CIFAR-10 dataset
The CIFAR-10 dataset consists of 60000 32×32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images.
The dataset is divided into five training batches and one test batch, each with 10000 images. The test batch contains exactly 1000 randomly-selected images from each class. The training batches contain the remaining images in random order, but some training batches may contain more images from one class than another. Between them, the training batches contain exactly 5000 images from each class.
Here are the classes in the dataset, as well as 10 random images from each:

Training an image classifier
- Load and normalizing the CIFAR10 training and test datasets using torchvision
- Define a Convolutional Neural Network
- Define a loss function
- Train the network on the training data
- Test the network on the test data
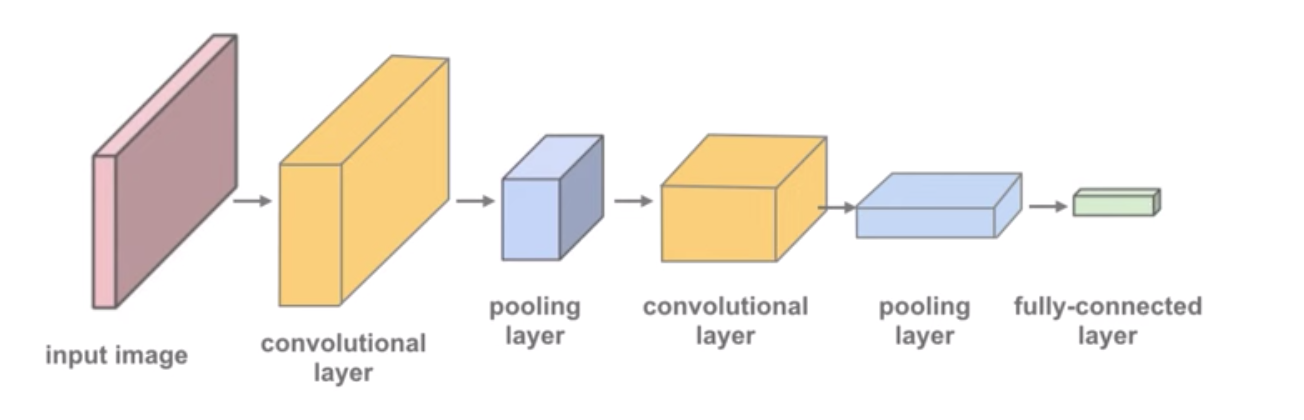
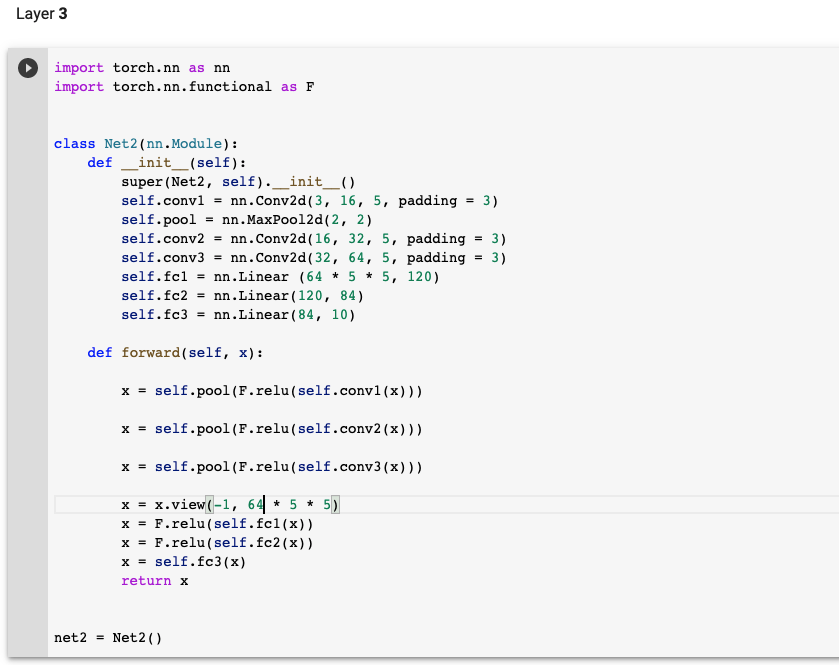
Define CNN model
The Conv2d layer transforms a 3-channel image to a 16-channel feature map, and the MaxPool2d layer halves the height and width. The feature map gets smaller as we add more layers, until we are finally left with a small feature map, which can be flattened into a vector. We can then add some fully connected layers at the end to get vector of size 10 for each image.
Setup Training system
After preparing dataset and defining network model, the next step is to setup the training system. To be more specific, we need to define Loss function, Optimizer and some other Hyper-parameters that support the training procedure.
Loss function
Loss function is the component of the training system quantifying the badness of the model. The choice of Loss function depends heavily on the the problem type. For numerical values, the most common cost functions is Square Error. For classification task, Cross-Entropy is commonly preferred. In this dataset, there are 10 classes, the proper loss function is clearly the Cross-Entropy loss. Softmax operation is also applied to map the result to range [0, 1] as related to probability.
Optimizer
After calculating the current loss of training’s specific state, a mechanism is needed to search and update the parameters for minimizing the loss value. As widely known, the most popular optimization algorithm for Neural Networks is Gradient Descent. Briefly, at a state, for each parameter, the optimizer will determined how to change its value to reach the lowest minima for the cost function.

Training the network
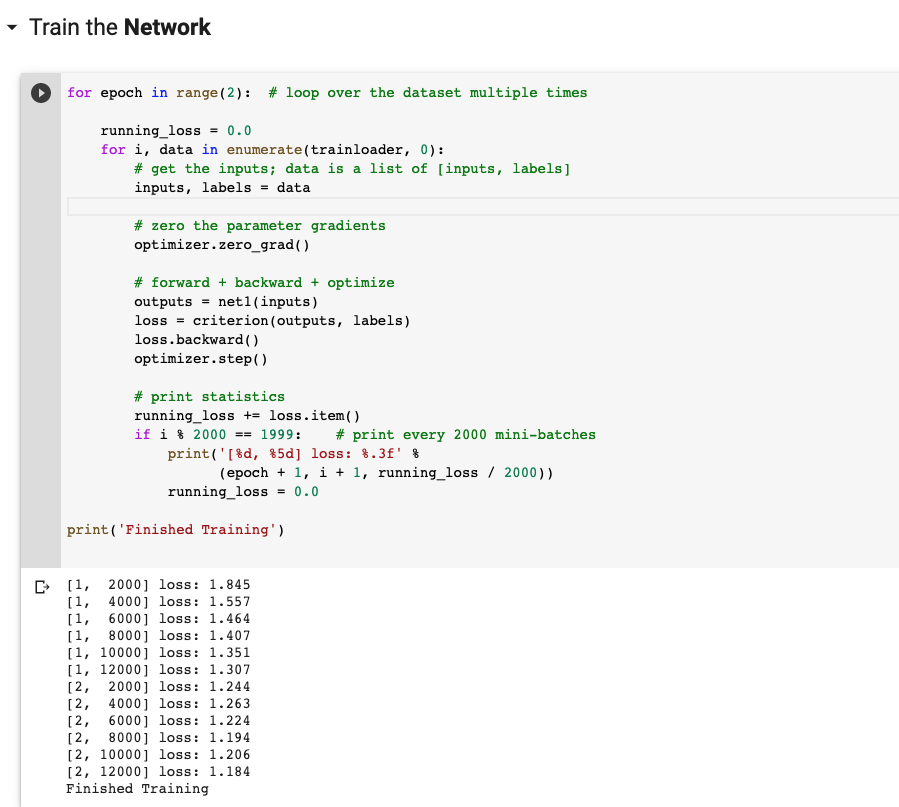
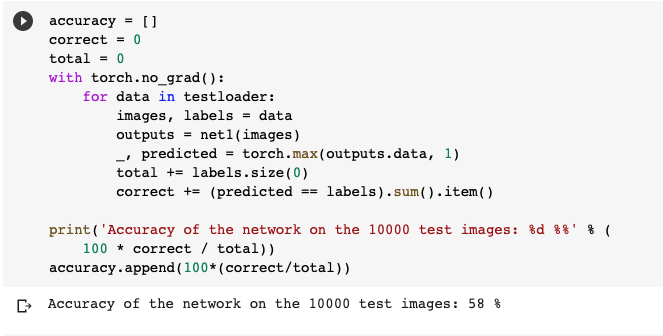
The accuracy of the two layer model
Layer 3
Layer 4

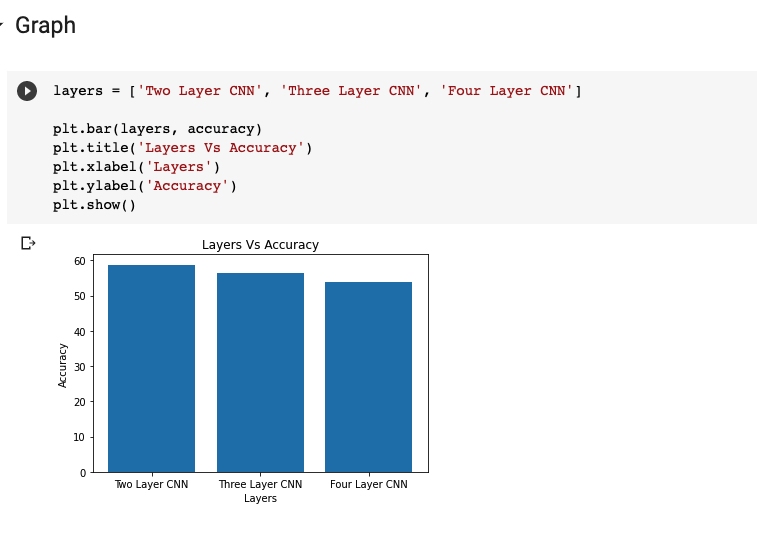
The graph